A Year Learning ML Infra
Introduction
I’m interested in Machine Learning Infrastructure (ML Infra) as it’s fusion of my core passions Distributed Learning, Parallel and GPU Computation, and Machine Learning. I’m less interested in ML Models and Data Science compared to classic Computer Science topics like Systems which made some parts of my ML journey a bit harder. The fact that I was also apart of a double major in CS and Business meant I did not have the time to take Linear Algebra which has proved to be a massive deficiency I hope to fill when I have the time.
CUDA C++ and GPU Architecture
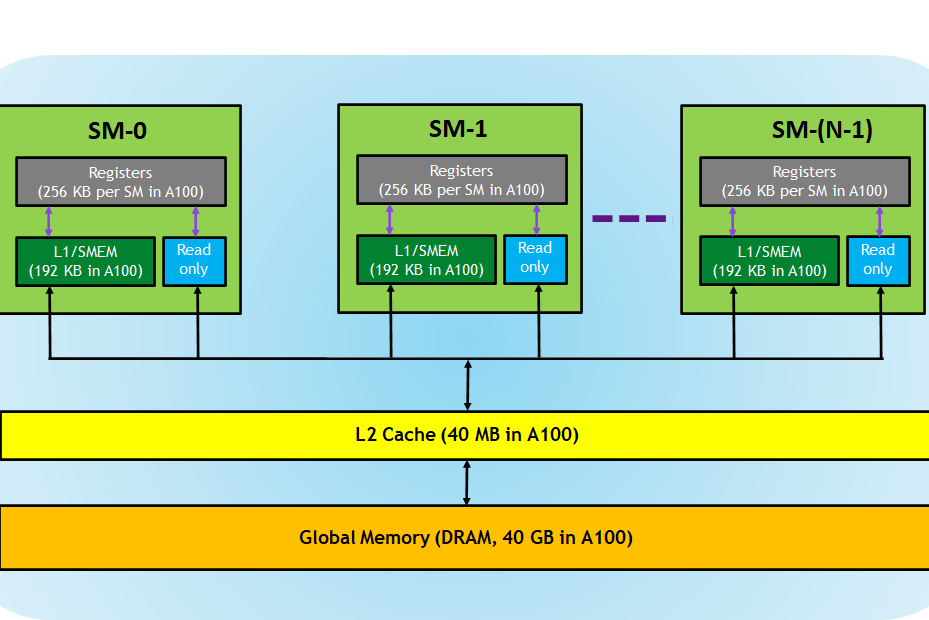
I’ve been intrigued by CUDA well before the war over NVIDIA GPUs and the training of AI models began. On the recommendation of a friend who led the ML Infrastructure at Robinhood, I dove into GPU Architecture and, naturally, CUDA C++. I discovered an exceptional resource provided by and NVIDIA with all the homework, solutions and recorded lectures. The course was paced just right, and having just completed a course in Operating Systems, I felt well-prepared with all the prerequisites. Understanding GPU Architecture concepts isn’t overly challenging, but parallelizing algorithms, which are trivial for CPUs, is incredibly tough. Writing an algorithm to add two vectors, for instance, requires substantial brainpower. It wasn’t until I was 10 lectures deep and after much practice that I managed to sum an array. The thing with CUDA is that, when you work at a large company like LinkedIn, writing GPU code is often abstracted away. I hope once day to work in a role where I can write CUDA directly. For now, even though I’m not great at writing CUDA, I feel I have a solid grasp of the benefits and limitations of GPUs and the complexities involved in writing for them. If I ever find myself fortunate enough to write CUDA code professionally, I know I can improve it.
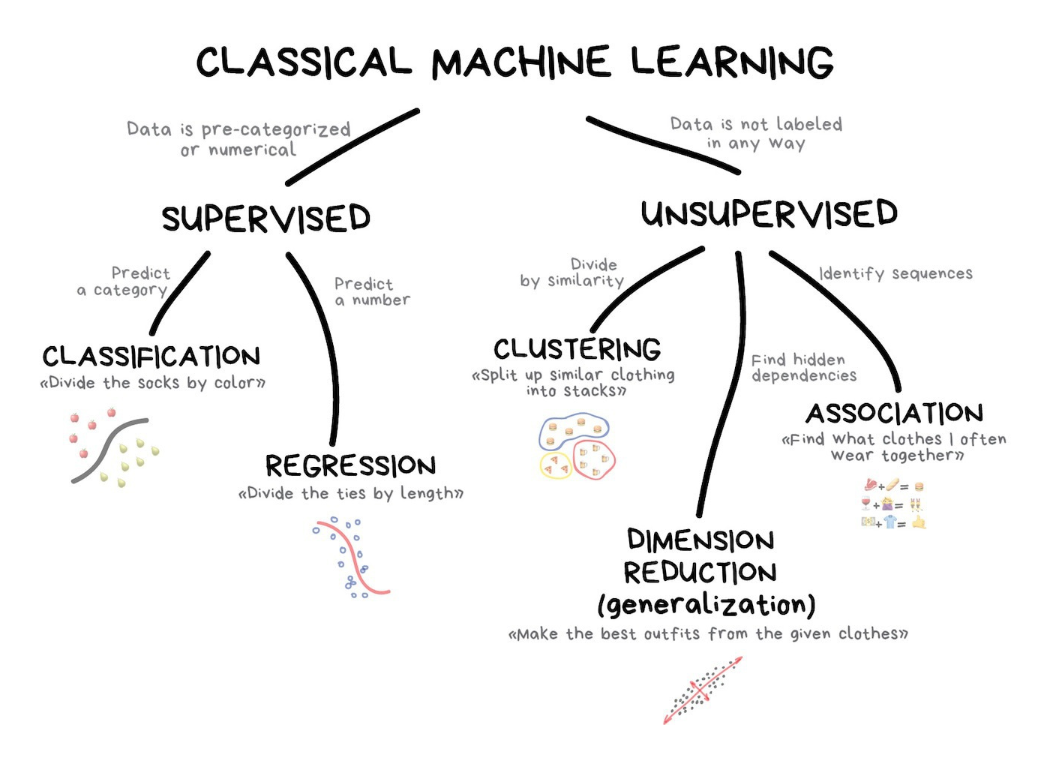
Classical Machine Learning
I needed to establish a foundational knowledge of ML as how can you build internal tools for ML Engineer’s if you don’t even know how an ML Engineer think’s or what they want. UBC’s Applied ML had all it’s lectures and content online and I completed about half the lectures and assignments. Although I didn’t complete the course, I like to keep watching when I have spare time. It’s very well made and not complex, you don’t need any Math knowledge, you use existing models from Scikit-learn instead of making them yourself.
Deep Dive into Deep Learning
The journey got steeper with deep learning mathematics. Lacking a background in linear algebra and multivariable calculus made concepts like Backpropagation challenging to grasp. As of writting, I still don’t understand. I’m unofficially taking Nueral Networks for which I don’t meet the prerequities and the professor is reknown in his field even working with Geoffrey Hinton at Google Brain but sometimes when his slides get heavy in Linear Algebra notation, I have no clue what’s going on. I would not say I am bad at Math, but it’s not possible to understand the proofs and notation without taking Linear Algebra. I still continue to attend since not every lecture is Math heavy and I still get a good amount of knowledge out of it. I managed to learn TensorFlow on Udemy, I really don’t like building ML Models or hyperparamater optimization, so I am getting through slower than anticipated. This is very much a high priority and WIP item for me. Once I establish a good baseline TensorFlow and Deep Learning knowledge, I’ll begin looking into how to actually perform distributed and GPU accelerated model training and running inference.

MLOps for Production
To wrap up my knowledge, I embarked on Andrew Ng’s MLOps course series, completing 1.5 of the four courses. This heavy program required a pause since I wanted to focus less on MLOps for now and more on Deep Learning, Distributed Training and Inference. The entire ML lifecycle is still something I intend to learn soon in detail with this course, but I am putting it off for a month or two till I finish my midterms.
Stanford’s ML Systems Class: A Perfect Fit
Finally, I discovered Stanford’s ML Systems class taught by Chip Huygen. I really liked this class; even though I felt I already possessed much of the knowledge from previous classes, it seemed like a consolidation of all the important things I’ve learned, distilled into concise lectures. I only found this course three days ago, but I’ve been reading a chapter every day, so I will likely finish soon. My accelerated pace is due to my familiarity with most of the content already.

MIT’s TinyML and Efficient ML Computing
This is a graduate-level MIT course I discovered, which assumes a very strong background in Math and Deep Learning that I do not possess. I don’t intend to understand 100% of this course, but I do selectively watch lectures on topics that interest me. Some are very math-heavy, which makes it difficult for me, while others are not. Given that it’s a graduate-level MIT class and I don’t meet the prerequisites, I don’t feel bad about struggling with some of the material. I’m extremely envious of those who can grasp everything presented in this class, as it is taught by Song Han, who is truly brilliant in this field.
Designing Data Intensive Applications
This book has nothing to do with ML but it’s in my opinion the only book you will need to read if you want to build a strong foundation in distributed systems, I read half of it in my second year after Computer Systems (before taking OS) and the content was so well written that even I understood everything the author was saying. Reading this book was actually fun and did not feel like a chore at all.

I Have a Dream - LinkedIn’s ML Infrastructure Team
Looking ahead, my goal is to join LinkedIn’s ML Infrastructure team, ideally working in Distributed Training, Model Inference, or MLOps. Here, I hope to apply my knowledge in tackling real-world challenges.
