Introduction
During my time at Intuit, I had the opportunity to work on various projects and learn new technologies. I worked on three projects, which are listed below. I have also included a brief description of the projects and the technologies used. I had many opportunities to pursue areas that interested me, and I was pleasantly surprised by the level of autonomy I had in choosing the projects that intrigued me the most.
Table of Contents
- Project 1: Retry Mechanism with AWS SQS
- Project 2: Codebase Refactoring for Reduced Coupling
- Project 3: Building a TypeScript and GraphQL Microservice with AWS Lambda
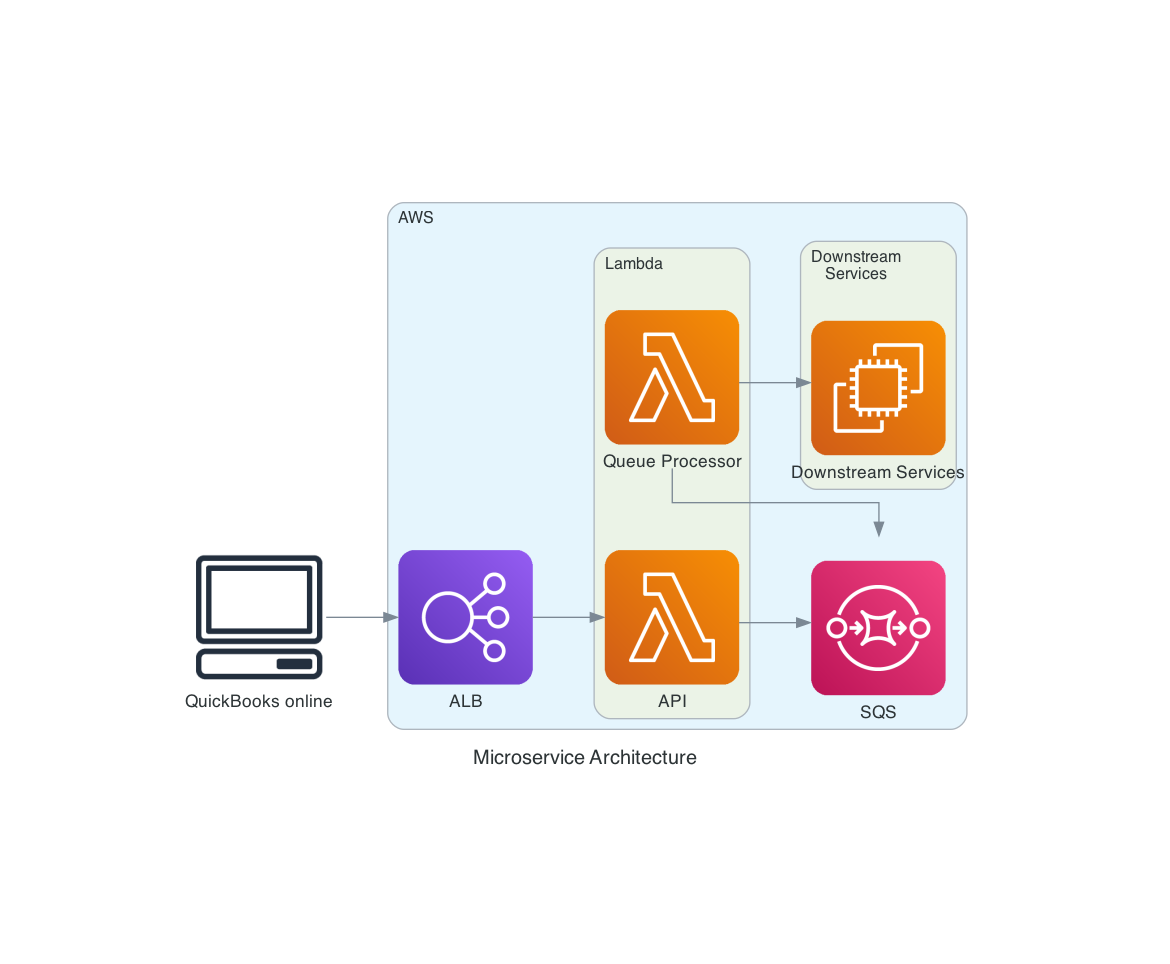
Project 1: Retry Mechanism with AWS SQS
When people called our API, there were often timeouts since some downstream APIs were slow, and once we reached a timeout, we would return an error, and the user would have to retry the request.
I was working with a more senior engineer on my team on a a retry mechanism so that we could retry the request if it failed. We used AWS SQS to implement this. We would send the request to SQS and immediately return a 200-level response. Then a Lambda would be triggered to pull from SQS and try to send the request to the downstream API. If the request failed, SQS would retry the request. We also had to implement a dead letter queue, which would store the request if it failed after a certain number of retries. Working with more senior engineers, as my first tickets were based around this feature, I got my first taste of Software Engineering and how to properly write clean code, use git, and use the debugger (which was a lifesaver).
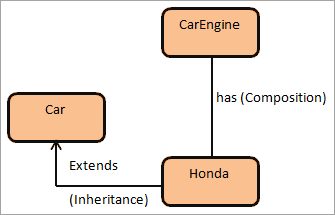
Project 2: Codebase Refactoring for Reduced Coupling
Inside our API, many of our service classes were tightly coupled, and it was hard to make changes to them without breaking other things. We wanted to refactor our codebase to stop all our service classes from inheriting from a REST client class and instead use dependency injection to inject an interface which supports the REST methods into the service classes. We wanted to move away from inheritance and instead use composition. This would allow us to swap out the REST client very easily and also make it easier to test our code as it’s easier to mock a dependency than a parent class.
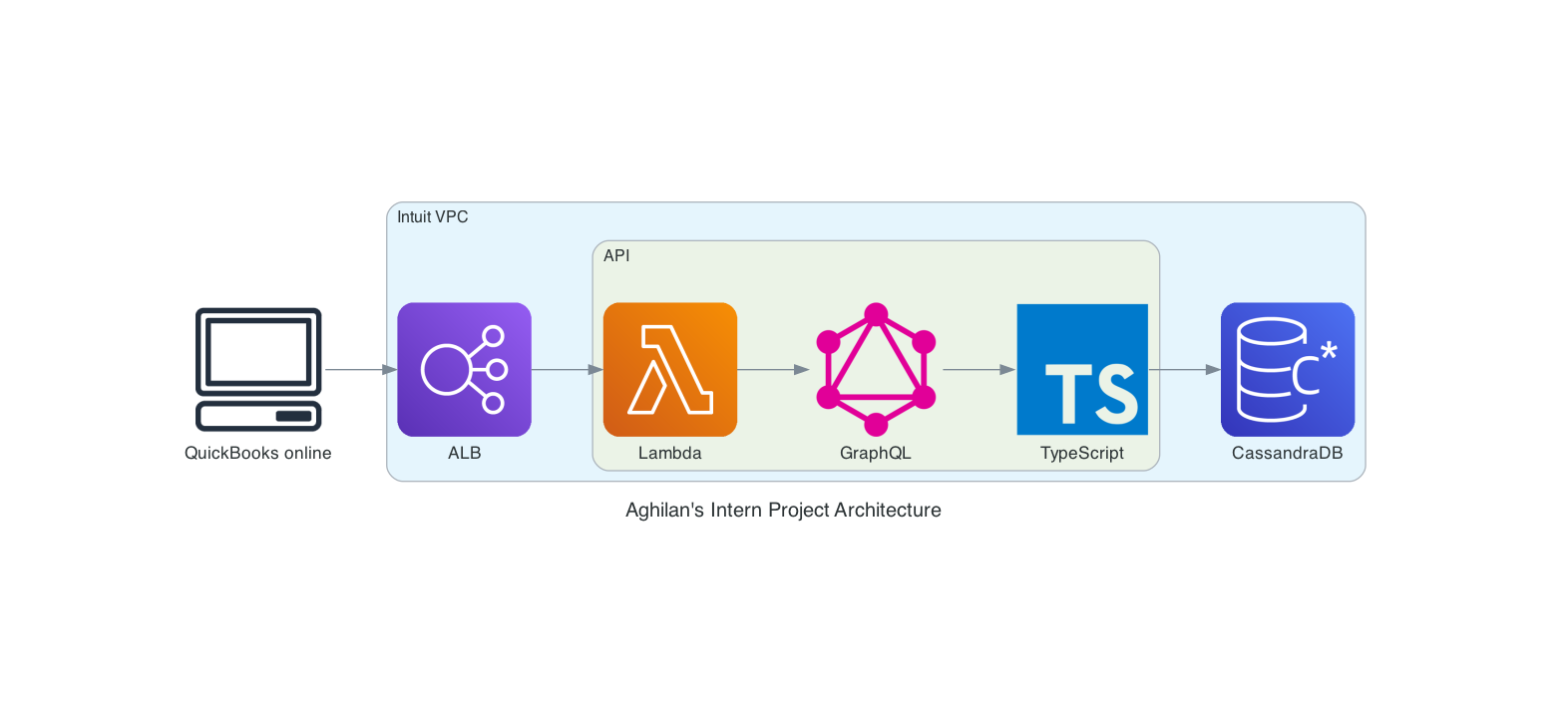
Project 3: Building a TypeScript and GraphQL Microservice with AWS Lambda
Background and Project Objectives
I heard a principal engineer on my team was starting a greenfield project, and I asked if I could help. He said yes, and I was able to work on this project for the rest of my internship. I was tasked with building out a microservice and choosing a database that would be used to store and retrieve data for this project. The microservice would be built using TypeScript and GraphQL and would be running on AWS Lambda. This service should be able to run in a distributed environment and be able to scale up and handle large throughput. Scaling the API was a task abstracted away from me given the serverless architecture, so I had one last thing to worry about (thanks Lambda). The real challenge was that the database should be able to handle high write throughput OLTP transactions while also allowing a daily CRON job to run OLAP queries on the data (two extremely different access patterns). It was also possible to do a daily dump of the data into a data lake where OLAP is optimized for, but this would be a last resort as it would be expensive and would require a lot of work to set up an entire ETL pipeline.
Based on the access patterns this service would have, where I would have large write throughput and few reads (apart from a daily CRON job), I evaluated my choices of DynamoDB, CassandraDB, and PostgreSQL. Our data had some relations, but our application does not require the ACID benefits associated with SQL and consequently, we did not want to pay the performance/scale issues associated with SQL. The data was also prone to often being in different forms, so I did not want to have to risk dealing with a migration.
I decided to use CassandraDB over DynamoDB as I was dealing with a write-heavy system, which CassandraDB is great for due to its Log-Structured Merge Tree implementation. With writes, you can write to the one in-memory memtable and then flush to the disk later, and with reads, you need to go and check possibly multiple on-disk SST Tables. In reality, the actual implementation of Cassandra is far more complex than just one data structure, but it still helps explain the tradeoffs well.
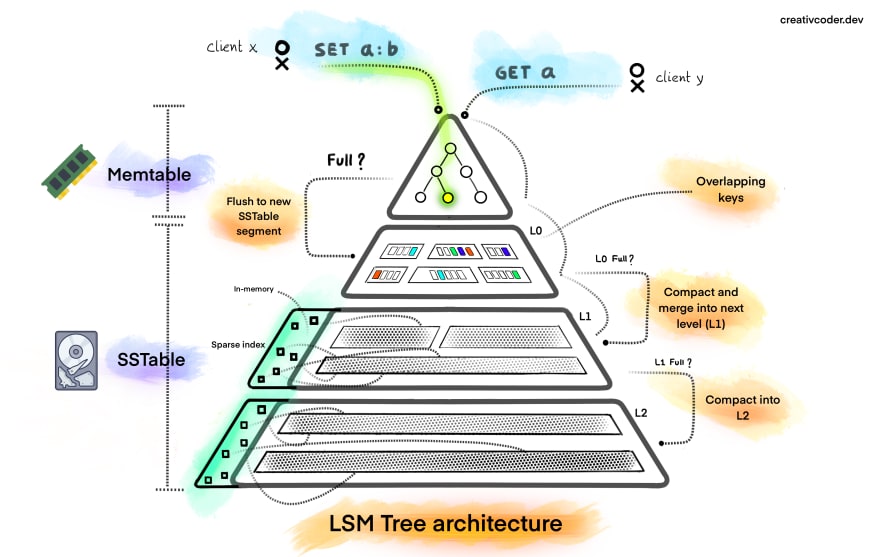
In order to support certain analytics queries, I learned a lot about how to properly utilize both the partition and clustering keys in CassandraDB and modeling the data in a way that would allow for efficient queries. I also learned about how to properly use secondary indexes in CassandraDB and the tradeoffs associated with them. One cool feature of Cassandra I found useful was the ability to have the clustering key be a date range so that I could query for all the data in a certain date range without scanning the entire table.
The rest of the time I spent building out the microservice, which would take requests from a web-browser client and then write their data to the DB. I also had to build out the support for endpoints supporting the more complex analytics queries, which took longer to execute, but it was okay since they were only run once a day. Before I knew it, my work was complete, and my time at Intuit was over. I had a truly great time and I am so grateful to have a team of people I can get help from who wanted nothing but the best for my growth.
